Statistik
Einige statistische Begriffe in Kurzform.
Fehler
Fehler 1. Art (Alpha-Fehler)
Liegt vor, wenn beim Hypothesentest die Nullhypothese verneint wird, obwohl sie in Wirklichkeit wahr ist (beruhend auf einer zufällig erhöhten bzw. niedrigeren Anzahl positiver Ergebnisse = falsch positive Ergebnisse).
Fehler 2. Art (Beta-Fehler)
Liegt vor, wenn beim Hypothesentest die Nullhypothese fälschlicherweise nicht verneint wird, obwohl die Alternativhypothese wahr ist.
Fehlerwahrscheinlichkeit 1. Art (Alpha-Risiko, Produzentenrisiko, blinder Alarm)
Wahrscheinlichkeit des Auftretens eines Fehlers 1. Art.
Fehlerwahrscheinlichkeit 2. Art (Beta-Risiko, Konsumentenrisiko, unterlassener Alarm)
Wahrscheinlichkeit des Auftretens eines Fehlers 2. Art.
Bestimmtheitsmaß R²
Das Bestimmtheitsmaß R-Quadrat gibt an, wie viel Prozent der Variation in der abhängigen Variable durch ein Regressionsmodell erklärt werden können.
Es misst die Güte der Anpassung des Modells an die Daten, also wie gut die unabhängigen Variablen des Modells die Varianz (Streuung) der abhängigen Variable erklären.
Skala:
Zwischen 0 (0 %) und 1 (100 %)
Interpretation:
0 (0 %): Datenpunkte liegen weit von der Regressionsgeraden entfernt; Modell erklärt die Streuung schlecht. Die unabhängigen Variablen erklären die Varianz der abhängigen Variable nicht.
1 (100 %): Datenpunkte liegen nahe an der Regressionsgeraden. Die unabhängigen Variablen erklären die gesamte Variation der abhängigen Variable.
Bonferroni-Korrektur
Durch die Bonferroni-Korrektur können Fehler 1. Art (falsch positive Ergebnisse) begrenzt werden, wenn mehrere statistische Tests gleichzeitig durchgeführt werden (Mehrfachtestung).
Dazu wird das ursprüngliche Signifikanzniveau (Alpha) durch die Anzahl der durchgeführten Tests geteilt. Dadurch entsteht ein strengeres, für jeden einzelnen Test angepasstes Signifikanzniveau.
Die Durchführung mehrerer Hypothesentests auf denselben Daten erhöht die Wahrscheinlichkeit, dass ein Ergebnis zufällig falsch-positiv ist (fälschlich als signifikant interpretiert wird).
Die Bonferroni-Korrektur verhindert diese “Alphafehler-Kumulierung” und verhindert einen Anstieg der Gesamtwahrscheinlichkeit für mindestens einen Fehler 1. Art über das ursprünglich definierte Niveau (z.B. 5 %).
Berechnung:
Ursprüngliches Alpha-Niveau (üblich: 0,05 = 5 %) für Einzeltest geteilt durch Anzahl der durchgeführten Einzeltests mit denselben Daten.
Ein Ergebnis gilt nur dann als statistisch signifikant, wenn der berechnete p-Wert des Einzeltests kleiner oder gleich dem neu berechneten, angepassten Alpha-Niveau ist.
Variablen
Nominalskalierung
Wert beinhaltet Wort / Namen (“Nomen”), z.B. Frage nach dem Beruf.
Dichotome Werte
Wert mit max. 2 Ausprägungen, wie z.B. ja / nein.
Ordinalskalierung
Absteigende oder aufsteigende Reihenfolge (“Ordnung”), nicht notwendigerweise mit gleichen Abständen.
T-Wert
Differenz von zwei Stichprobenmittelwerten, angegeben in Einheiten des Standardfehlers.
Z-Score / Z-Wert
Entfernung eines Datenpunktes vom Mittelwert des Datensatzes, angegeben in Standardabweichungen.
Standardabweichung
Wurzel aus dem Durchschnitt der quadrierten Entfernung der Datenpunkte vom Mittelwert.
In anderen Worten:
- Abweichung vom Mittelwert x Abweichung vom Mittelwert wird für jeden Datensatz (Probanden) errechnet
- Dieser Wert wird von allen Datensätzen (Probanden) summiert
- Vom Ergebnis wird die Wurzel gebildet
Maß der Streuung der Daten um den arithmetischen Mittelwert.
Einheit: Wie Messwerte.
Interpretation:
Kleine Standardabweichung: Die Datenpunkte liegen nah am Durchschnitt. Große Standardabweichung: Die Daten sind breit gestreut.
Anwendungsbereich:
Werte, die mindestens Intervallskalenniveau haben, mithin einen Mittelwert bilden können.
Vorhersagewerte
Sensitivität
Sensitivität ist das Gegenstück zur falsch-negativen Rate. Die falsch-negative Rate plus Sensitivität ergeben 100%.
Die Falsch-positivrate ist mithin 1 minus Sensitivität.
Sensitivität ist hier also das Maß, wieviele ADHS-Betroffene richtig als ADHS-Betroffene erkannt werden.
Spezifität
Spezifität: Wahrscheinlichkeit, dass Patienten ohne die Krankheit ein negatives Testergebnis haben (Richtig-negativ-Rate).
Spezifität ist das Maß, wie viele Gesunde richtig als Gesunde erkannt werden.
ROC
ROC-Kurve: Receiver operation characteristics - Kurve
Die ROC-Kurve ist die grafische Darstellung der wahr-positiven Ergebnisse (Anzahl der wahr-positiven Ergebnisse bzw. Probanden mit Krankheit) im Vergleich zu den falsch-positiven Ergebnissen (Anzahl der Fehlalarme bzw. Probanden ohne Krankheit) für eine Reihe von Grenzwerten. Die ROC-Kurve zeigt grafisch die Schnittmenge zwischen der Sensitivität und der Spezifität, wenn der Grenzwert angepasst ist Üblich:
- y-Achse bildet wahr-positive Menge ab
- x-Achse bildet die falsch-positive Menge ab
AUC
Fläche unter der ROC-Kurve (Area under the curve, AUC).
Je größer die Fläche unter der ROC-Kurve, desto besser unterscheidet der Test zwischen Probanden mit und ohne Krankheit.
Trennschärfe. 0,5 (= 50 %) = Zufall; 1 (= 100 %) = perfekt
Interpretation:
0,5: Zufall
0,6 – 0,7: schlecht
0,7 – 0,8: annehmbar
0,8 – 0,9: gut
0,9 – 1,0: hervorragend
Korrelation
Korrelation vs. Kausalität
Eine Korrelation ist Voraussetzung für eine Kausalität, sagt aber noch nicht, dass eine Kausalität vorliegt.
Beispiel: Bei Kindern korreliert die Körpergröße stark mit den mathematischen Kenntnissen, ist aber keineswegs kausal. Es liegt eine “Scheinkorrelation” vor, obwohl Scheinkausalität gemeint ist, denn Korrelation besteht ja.
Werden Experimente so gestaltet, dass ausschließlich eine Variable verändert wird, kann dies eine Aussage über Kausalität erlauben.
Im Beispiel mit der Körpergröße und den Mathematikkenntnissen könnten dazu lauter gleich alte Kinder mit gleichem Gewicht in derselben Klassenstufe derselben Schulart miteinander verglichen werden. Es ist absehbar, dass die Körpergröße dann nicht mehr mit den Mathematikkenntnissen korreliert, und infolgedessen auch nicht kausal sein kann.
Die Berechnung von Partialkorrelationen erlaubt dies auch, ohne dass alle anderen Variablen unverändert bleiben.
Pearson-Korrelationskoeffizient (r, Produkt-Moment-Korrelationskoeffizient)
- Summe der Kreuzprodukte aller Probanden. Genauer: Summe der Werte von allen Probanden aus der Abweichung der Werte eines Probanden vom Mittelwert aller Probanden der X-Achse mal demselben Wert der Y-Achse.
- Kovarianz: ermittelter Wert wird durch Anzahl der Probanden geteilt. Damit wird Wert unabhängig von der Größe der Probandenzahl,
- Kovarianz wird durch Produkt der Standardabweichungen von Y und X geteilt. Damit wird Wert unabhängig von der verwendeten Maßeinheit und somit über verschiedene Testsettings vergleichbar.
Bezeichner: r
Anwendungsbereich:
- Werte, die mindestens Intervallskalenniveau
- bei metrischen Merkmalen, wenn ein linearer Zusammenhang vermutet wird
Interpretation:
r = - 1: perfekte negative Korrelation
r = - 0,5 und höher: hohe negative Korrelation
r = - 0,3: mittlere negative Korrelation
r = - 0,1: niedrige negative Korrelation
r = 0: keine Korrelation
r = 0,1: niedrige positive Korrelation
r = 0,3: mittlere positive Korrelation
r = 0,5 und höher: hohe positive Korrelation
r = 1: perfekte positive Korrelation
Chi-Quadrat, χ2
Misst die Stärke der Korrelation zwischen nominalskalierten Merkmalen.
Bezeichner: χ2
Interpretation:
χ2 = 0: keinerlei Korrelation
Wert nach oben ist unbegrenzt
Phi-Koeffizient für Korrelation dichotomer Werte
Phi-Koeffizient = Wurzel aus (Chi-Quadrat / Anzahl der Werte)
Berechnung aus Vierfeldertafel
| X: nein | X: ja | |
|---|---|---|
| Y: nein | A | B |
| Y: ja | C | D |
Phi-Koeffizient = (A x D - B x C) geteilt durch Wurzel aus ((A + B) x (C + D) x (A + C) x (B + D))
Phi normiert den Chi-Quadrat-Koeffizienten auf Werte zwischen 0 und 1, was die Ergebnisse vergleichbar macht.
Anwendungsbereich:
- dichotome Werte (Wert mit max. 2 Ausprägungen, wie z.B. ja / nein)
- nur im Falle einer Vierfeldertafel (2 × 2 - Tabelle) anwendbar
Interpretation:
Phi = 0: keine Korrelation
Phi = 0,1: niedrige Korrelation
Phi = 0,3: mittlere Korrelation
Phi = 0,5 und höher: hohe Korrelation
Phi = 1: perfekte Korrelation
Cramers V
Cramers V misst die Stärke der Korrelation zwischen nominalskalierten Merkmalen.
Berechnung:
- Chi-Quadrat wird geteilt durch (Anzahl der Messwerte mal [Minimum der Zeilen- und Spaltenzahl der Kreuztabelle minus 1])
- Aus dem Ergebnis wird die Wurzel gezogen
Unterer Wert: 0 (keine Korrelation)
Oberer Wert: 1 (maximaler Zusammenhang)
Anwendungsbereich:
- Kreuztabellen mit mindestens 2 x 2 Feldern
Spearmans Rho
Andere Namen: Spearman-Korrelation, Spearman-Rangkorrelation, Rangkorrelation, Rangkorrelationskoeffizient
Zweck:
Messung der Korrelation von Rangfolgen
Berechnung:
Rho = 1 - (6 × Summe der quadrierten Rangdifferenzen) / (Anzahl Datensätze × [Anzahl Datensätze x Anzahl Datensätze - 1]).
Anwendungsbereich:
- mindestens eines der zwei Merkmale ist nur ordinalskaliert und nicht intervallskaliert
oder - bei metrischen Merkmalen, wenn kein linearer Zusammenhang vermutet wird (bei einem linearen Zusammenhang ist der Pearson-Korrelationskoeffizient geeignet).
Interpretation:
Rho = - 1: perfekte negative Korrelation
Rho = - 0,5 und höher: hohe negative Korrelation
Rho = - 0,3: mittlere negative Korrelation
Rho = - 0,1: niedrige negative Korrelation
Rho = 0: keine Korrelation
Rho = 0,1: niedrige positive Korrelation
Rho = 0,3: mittlere positive Korrelation
Rho = 0,5 und höher: hohe positive Korrelation
Rho = 1: perfekte positive Korrelation
Kendals Tau
Andere Namen: Kendall-Rangkorrelationskoeffizient, Kendall’s τ (griechischer Buchstabe Tau), Kendalls Konkordanzkoeffizient
Zweck:
Messung der Korrelation von ordinalskalierten Werten (Rangfolgen)
Berechnung:
Tau = (Konkordante Paare - Diskordante Paare) / (Konkordante Paare + Diskordante Paare)
Anwendungsbereich:
- Daten müssen nicht normalverteilt sein
- Beide Variablen müssen nur ordinales Skalenniveau haben
- besser als Spearmans Rho, wenn sehr wenige Daten mit vielen Rangbindungen vorliegen
Interpretation:
Tau = - 1: perfekte negative Korrelation
Tau = - 0,8: hohe negative Korrelation
Tau = - 0,5: mittlere negative Korrelation
Tau = - 0,2: niedrige negative Korrelation
Tau = 0: keine Korrelation
Tau = 0,2: niedrige positive Korrelation
Tau = 0,5: mittlere positive Korrelation
Tau = 0,8: hohe positive Korrelation
Tau = 1: perfekte positive Korrelation
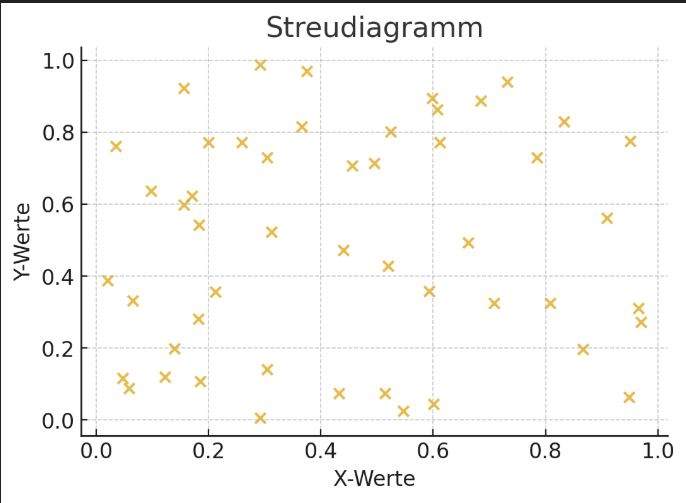
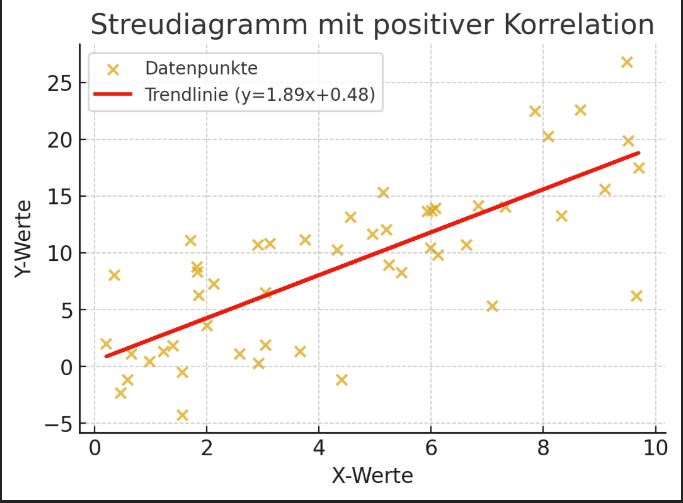
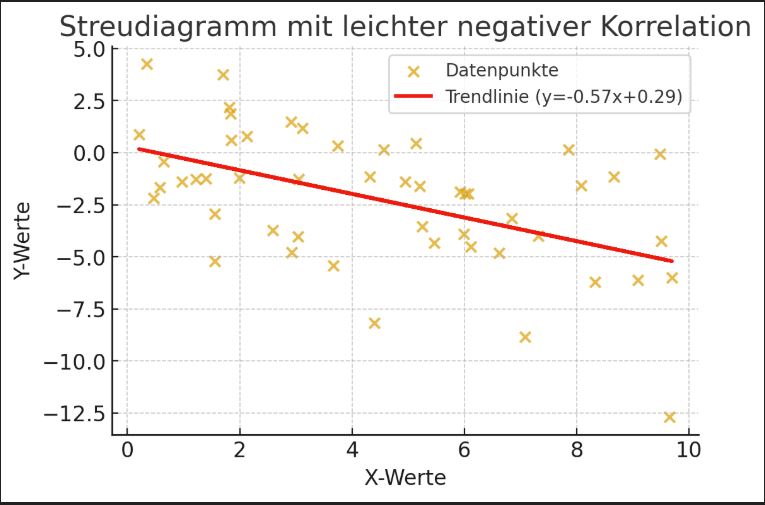
Streudiagramme
Die nachfolgenden Streudiagramme veranschaulichen, wie Datenpunkte und Trendlinien in verschiedenen Korrelationsmustern aussehen.
Keine Korrelation:
Mittlere positive Korrelation:
Leicht negative Korrelation:
Konsistenz
Cronbachs Alpha-Koeffizient (α)
Cronbachs Alpha misst die interne Konsistenz einer Skala oder eines Tests.
Er gibt an, wie gut eine Gruppe von Fragen (Items) ein einziges, latentes Konstrukt erfasst und wie zuverlässig die Skala insgesamt ist. Ein höherer Alpha-Wert, der zwischen 0 und 1 liegt, deutet auf eine bessere interne Konsistenz hin.
Interpretation:
0,60 – 0,67: Mangelhafte oder fragwürdige interne Konsistenz; die Items sollten möglicherweise nicht zusammengefasst werden.
0,70 – 0,79: Akzeptable interne Konsistenz.
0,80 – 0,89: Gute interne Konsistenz.
ab 0,90: Hervorragende interne Konsistenz.
Cronbachs Alpha steigt mit der Anzahl der Items in der Skala, was die Ergebnisse verzerren kann.
Verwendung: Die Items sollten
- inhaltlich zusammenpassen
- die gleiche Richtung haben (andernfalls ist eine Umkodierung erforderlich)
- sollten einen ähnlichen Wertebereich haben.
Regression
Lineare Regression
Lineare Regression dient der Vorhersage einer abhängigen Variable mithilfe einer oder mehrerer unabhängiger Variablen unter Verwendung eines linearen Modells.
Lineare Regression schätzt die Koeffizienten für eine lineare Gleichung, die eine gerade Linie (bei mehreren Variablen: Oberfläche) darstellt, die die Diskrepanzen zwischen vorhergesagten und tatsächlichen Werten minimiert, oft mittels der Methode der kleinsten Quadrate.
Einfache lineare Regression: Nutzt nur eine unabhängige Variable, um die abhängige Variable zu erklären.
Multiple lineare Regression: Nutzt mehrere unabhängige Variablen, um die abhängige Variable zu erklären.
Abhängige Variable: Die Variable, die vorhergesagt werden soll.
Unabhängige Variable(n): Die zur Vorhersage verwendete(n) Variable(n).
Lineares Modell: Ein Modell, das eine lineare Beziehung zwischen den Variablen annimmt.
Methode der kleinsten Quadrate: Ein Rechenverfahren, um die passendste Linie zu finden, indem die Summe der quadrierten Fehler minimiert wird.
Ziele und Anwendungen:
Ursachenanalyse: Untersuchen, ob und wie stark eine abhängige Variable mit einer unabhängigen Variable zusammenhängt.
Wirkungsanalyse: Verstehen, wie sich die abhängige Variable ändert, wenn sich die unabhängige(n) Variable(n) ändern.
Prognose: Vorhersagen von Werten der abhängigen Variable basierend auf den Werten der unabhängigen Variablen.
Voraussetzungen:
Variablen haben eine lineare Beziehung zueinander.
Die abhängige Variable ist mindestens intervallskaliert.
Wenige Ausreißer in den Daten, da Ausreißer die Ergebnisse stark beeinflussen können.
Logistische Regression
Logistische Regression dient der Vorhersage der Wahrscheinlichkeit eines binären Ereignisses (z. B. Ja/Nein, Erfolg/Misserfolg) in Abhängigkeit von einer oder mehrerer unabhängiger Variablen.
Während lineare Regression kontinuierliche Werte vorhersagt, erzeugt logistische Regression mittels der Sigmoidfunktion (inverse Logit-Funktion) eine s-förmige Kurve, die Wahrscheinlichkeiten zwischen 0 und 1 liefert.
Logistische Regression wird häufig zur Klassifizierung eingesetzt (z.B. Betrugserkennung auf der Basis von Datenmustern oder Krankheitsvorhersage auf der Basis von Faktoren wie Alter, Rauchen, Geschlecht etc.).
Ergebnis: kategoriale Variable mit zwei möglichen Ausprägungen (binäre abhängige Variable).
Die Einflussfaktoren, die die Wahrscheinlichkeit des Ergebnisses beeinflussen (unabhängige Variablen), können numerisch oder kategorial sein.
Logistische Funktion (Sigmoid): Diese Funktion bildet die Beziehung zwischen den unabhängigen Variablen und der binären abhängigen Variablen ab. Sie wandelt eine lineare Kombination der Eingabefeatures in einen Wahrscheinlichkeitswert zwischen 0 und 1 um.
Vorhersage der Wahrscheinlichkeit: Das Modell schätzt die Wahrscheinlichkeit, dass eine Beobachtung zu einer der beiden Kategorien gehört.
ANOVA
ANOVA (Varianzanalyse, Analysis of Variance) dient dazu, signifikante Unterschiede zwischen den Mittelwerten von mehr als zwei Gruppen zu testen.
ANOVA ist eine Erweiterung des t-Tests, der nur zwei Gruppen vergleicht. ANOVA vergleicht die Varianz zwischen drei oder mehr Gruppen mit der Varianz innerhalb der Gruppen, um festzustellen, ob die Unterschiede der Gruppenmittelwerte statistisch signifikant sind.
Berechnung:
F-Verhältnis = Varianz zwischen den Gruppen geteilt durch Varianz innerhalb der Gruppen.
Interpretation:
Je höher das F-Verhältnis, desto größer sind die Unterschiede zwischen den Gruppen im Vergleich zu den zufälligen Unterschiede innerhalb der Gruppen.
Einfaktorielle ANOVA
Untersucht den Einfluss einer einzigen unabhängigen Variable auf eine abhängige Variable.
Mehrfaktorielle ANOVA
Untersucht den Einfluss von zwei oder mehr unabhängigen Variablen.
MANOVA
MANOVA (multivariate Varianzanalyse) dient der Analyse von Abweichungen zwischen zwei oder mehr Gruppen, wenn es mehrere abhängige Variablen gibt.
Ziel:
Festzustellen, ob sich die Mittelwerte der abhängigen Variablen zwischen den Gruppen signifikant unterscheiden, unter Berücksichtigung der Wechselbeziehungen zwischen den Variablen.
ANCOVA
ANCOVA (Analyse der Kovarianz) ist eine statistische Methode zur Analyse von Kovarianz. ANCOVA verbindet Varianzanalyse (ANOVA) mit linearer Regression.
Im Vergleich zur ANOVA berücksichtigt die ANCOVA zusätzlich zur unabhängigen Variable eine weitere metrische Variable, die Kovariate.
Ziel:
Untersuchung des Einflusses einer oder mehrerer unabhängiger Variablen auf eine abhängige Variable unter Herausrechnung der Wirkung einer oder mehrerer Kovariaten (Störgrößen).
Beispiel:
Untersuchung verschiedener Stimulanzien (unabhängige Variable), wobei die Einnahme von Koffein (Kovariate) kontrolliert wird, um die Häufigkeit der Medikamentennebenwirkungen (abhängige Variable) zu vergleichen.
MANCOVA
Mancova (Multivariate Analysis of Covariance) ist ein statistisches Verfahren zur Analyse des Unterschieds der Mittelwerte mehrerer abhängiger Variablen zwischen verschiedenen Gruppen bei gleichzeitiger Kontrolle der Auswirkungen einer oder mehrerer Kovariaten (Störvariablen).
Mancova ist eine Erweiterung der Manova (multivariate Varianzanalyse) und der Ancova (Analyse der Kovarianz), die es ermöglicht, mehrere abhängige Variablen gleichzeitig zu analysieren und gleichzeitig störende Einflüsse von Kovariaten zu eliminieren.
Effektstärke
Mittelwertdifferenz, SMD, Cohens’ d
Dient dazu, den Einfluss unterschiedlicher Skalen zu neutralisieren und dadurch Tests vergleichbar zu machen.
Berechnung:
(Mittelwert der Veränderung bei Verum minus Mittelwert der Veränderungen bei Plazebo) geteilt durch (gepoolte) Standardabweichung
Interpretation:
Cohen’s d bis 0,2: sehr klein, nur statistisch feststellbar
Cohen’s d 0,2 bis 0,5: klein
- ab 0,5 am Individuum erkennbar
Cohen’s d 0,5 bis 0,8: mittel
Cohen’s d ab 0,8: stark
Beta-Koeffizient
Beta-Koeffizient ist der Regressionskoeffizient nach Umwandlung (Standardisierung) der abhängigen Variable und unabhängigen Variablen in z-Werte.
Dient zur Berechnung der Effektstärke in Regressionsanalysen.
Interpretation:
Beta-Koeffizient bis 0,1: sehr klein
Beta-Koeffizient 0,1 bis 0,3: klein
Beta-Koeffizient 0,3 bis 0,5: mittel
Beta-Koeffizient ab 0,5: stark
Wahrscheinlichkeit
Odd Risk (OR)
Verhältnis zweier “Odds” (Erfolgswahrscheinlichkeit geteilt durch Misserfolgswahrscheinlichkeit).
Verwendung häufig in Fall-Kontroll-Studien, um den Zusammenhang zwischen einer Exposition (z.B. Rauchen) und einem Ergebnis (z.B. Lungenkrebs) zu messen.
Hazard Risk (HR)
Verhältnis der sogenannten “Hazard Rates” (momentanes Risiko eines Ereignisses in einem bestimmten Zeitraum) zwischen zwei Gruppen.
Verwendung insbesondere in Überlebenszeitanalysen, um die Auswirkungen einer Behandlung auf die Zeit bis zum Ereignis (z.B. Tod) zu untersuchen.
p-Wert
Interpretation:
- p < .05* signifikant
- p < .01** hoch signifikant
- p < .001*** höchst signifikant
Number needed to…
Number needed to treat, NNT
Die Number needed to treat (Anzahl notwendiger Behandlungen, NNT) ist die statistisch notwendige Behandlungesanzahl, die im Vergleich zu einer Alternativbehandlung (meist Placebo oder Warteliste) einen zusätzlichen positiven Ausgang erreicht. Berrechnet wird NNT als Kehrwert der absoluten Risikoreduktion.
Beträgt beispielsweise der prozentuale Unterschied zwischen dem Anteil der Responder in der Wirkgruppe und in der Placebo-Gruppe 11 %-Punkte, ist der Kehrwert 9 die NNT.1
Number needed to harm, NNH
Anzahl der notwendigen Behandlungen, die nötig sind, um eine Nebenwirkung auszulösen.
Number needed to screen, NNS
Anzahl der notwendigen Screeningvorgänge, die nötig sind, um ein Risiko (Todesfall, unerwünschtes Ereignis) zu vermeiden.
Online-Statistik-Rechner
Während für professionelle Statistikauswertungen spezialisierte Programme verwendet werden (MATLAB, Statistica, SPSS oder auch freie Software wie PSPP, R, gretl)23, die weitaus leistungsfähiger sind als Excel, gibt es auch einige Online-Rechner, die einfache statistische Analysen ermöglichen.
Numiqo Onlinerechner Deskriptive Statistik:
- Hypothesentest
- Chi-Quadrat-Test
- t-Test
- Abhängiger t-Test
- ANOVA
- Dreifaktorielle ANOVA
- Mixed ANOVA
- Mann-Whitney U-Test
- Wilcoxon-Test
- Kruskal-Wallis-Test
- Friedman-Test
- Binomialtest